



Pierwszym etapem jest wczytanie danych i wybór zbioru danych do klasyfikacji oraz podział zbioru danych na treningowy i testowy poprzez wydzielenie części danych (np. 10 lub 20%). Wydzielenie zbioru walidacyjnego nastąpi automatycznie w aplikacji. Następnie należy wybrać przycisk Start Session.
Następnie aplikacja umożliwia wybór klasyfikatora – czyli modelu, który przeanalizuje dane tak, aby jak najlepiej odzwierciedlić zachodzące w nich zależności. Automatycznie wybrany jest klasyfikator drzewa (Tree). Wczytane dane można podejrzeć w zakładce ScatterPlot.
W ramach laboratorium należy wybrać dodatkowo naukę innych rozwiązań, np. Logistic Regression, Support Vector Machine, k-Nearest Neighbours lub płytką sieć neuronową. W zakładce Summary można dowolnie zmieniać parametry każdego modelu oraz wybierać cechy, na podstawie których model będzie się uczył i klasyfikował.
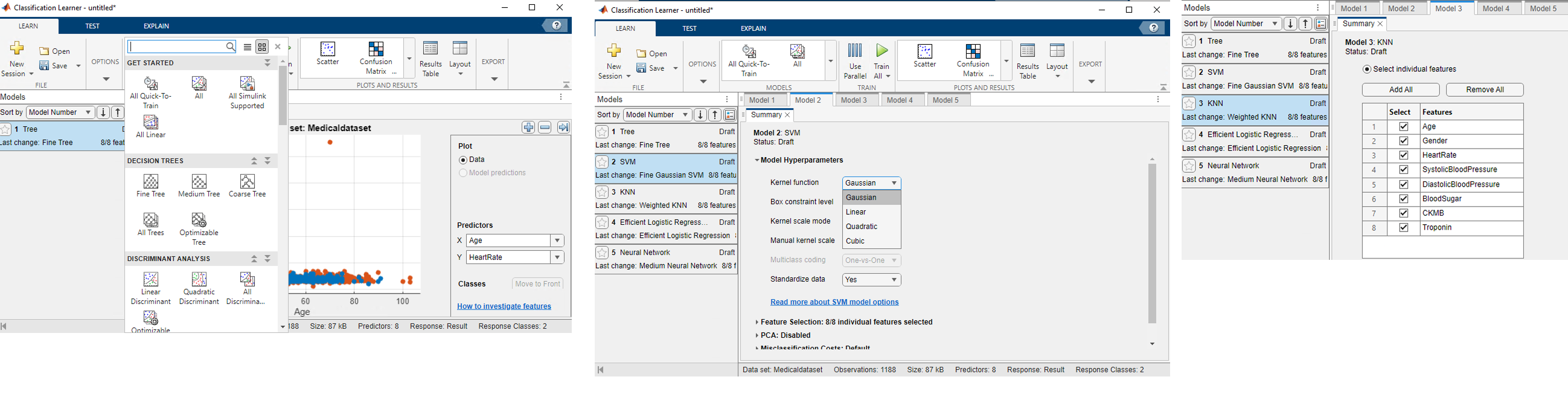
Gdy zakończymy edycję, należy wybrać zieloną strzałkę Train All, co spowoduje uruchomienie nauki. Z lewej strony obserwować można postęp nauki. Na zakończenie pojawi się okno z macierzą błędów uzyskaną dla zbioru walidacyjnego.
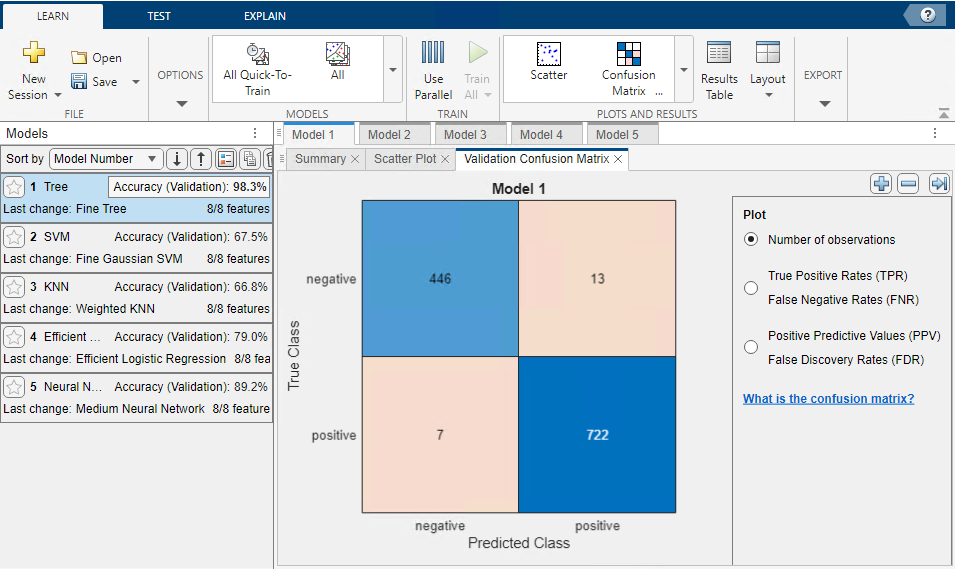
Następnym etapem jest więc sprawdzenie działania modeli na nowych danych. W tym celu należy uruchomić zakładkę TEST a następnie nacisnąć zieloną strzałkę Test All i znajdujący się na prawo Confusion Matrix (Test). Pozwoli to na ocenę, jak nasze modele radzą sobie na nowych danych, których wcześniej nie ,,widziały”.
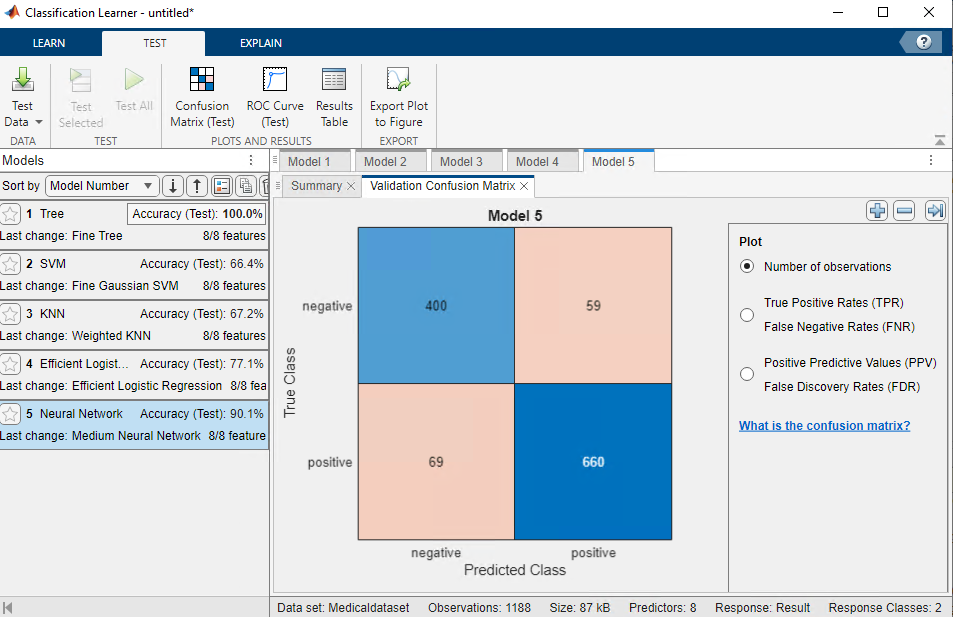
Ostatnim etapem jest określenie, jakie cechy miały największy wpływ na decyzję tych modeli. W przypadku prostych rozwiązań możliwe jest zbadanie, na podstawie jakich argumentów wejściowych podjęto daną etykietą na wyjściu. W tym celu należy wybrać zakładkę EXPLAIN i Local Shapley.
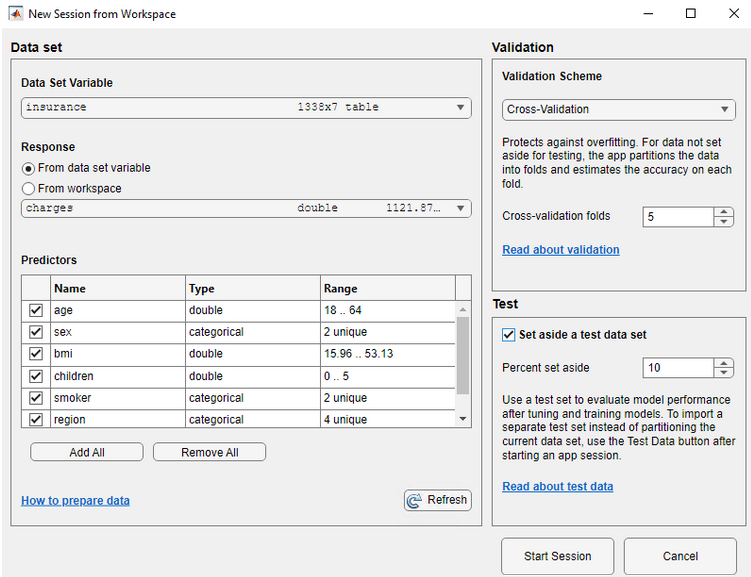
Pierwszym etapem jest wczytanie danych i wybór zbioru danych do regresji oraz podział zbioru danych na treningowy i testowy poprzez wydzielenie części danych (np. 10 lub 20%). Wydzielenie zbioru walidacyjnego nastąpi automatycznie w aplikacji. Następnie należy wybrać przycisk Start Session.
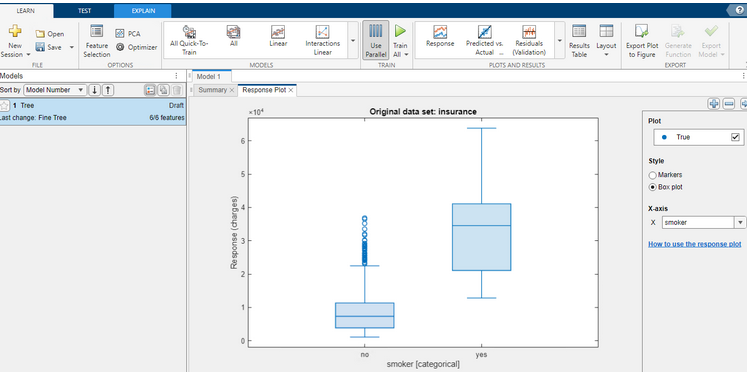
W zakładce Response Plot można sprawdzić, jak rozkładały się koszty ubezpieczenia (charges) w zależności od różnych informacji – wieku, płci itp. Informacje te można przedstawić jako wykresy rozrzutu (Style – Markers) lub wykresy pudełkowe (Style – Box plot).
Następnie wybieramy klasyfikatory: domyślnie wybrane jest drzewo regresji, dodatkowo można wybrać Linear Regression, Support Vector Machines i inne klasyfikatory.
W zakładce Summary można modyfikować parametry wybranego modelu i wybierać cechy.

Następnie należy wybrać zieloną strzałkę Train All aby rozpocząć naukę. W przypadku regresji miarą dokładności jest błąd między wartościami w zbiorze (charges) a przewidzianymi przez model. Interesuje nas więc ten model, dla którego wartość błędu jest jak najmniejsza.
Po zakończeniu nauki należy wybrać zakładkę TEST a następnie kliknąć zieloną strzałkę Test All.
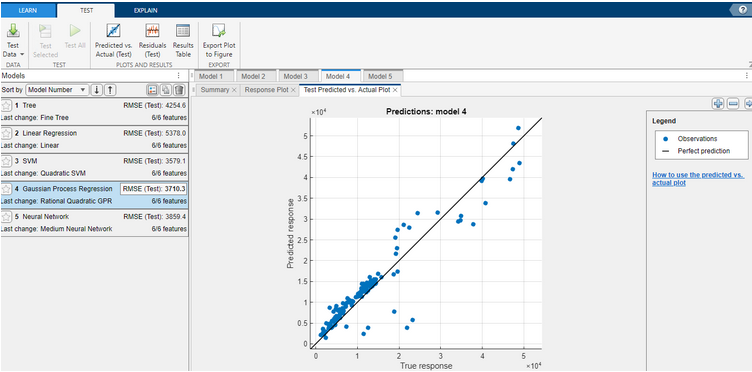
Wybierając przycisk Predicted vs Actual (test) możemy sprawdzić, w jakim stopniu odpowiedzi udzielane przez model różniły się od wartości rzeczywistych. Im lepiej model przewiduje, tym bliżej przekątnej znajdują się punkty.
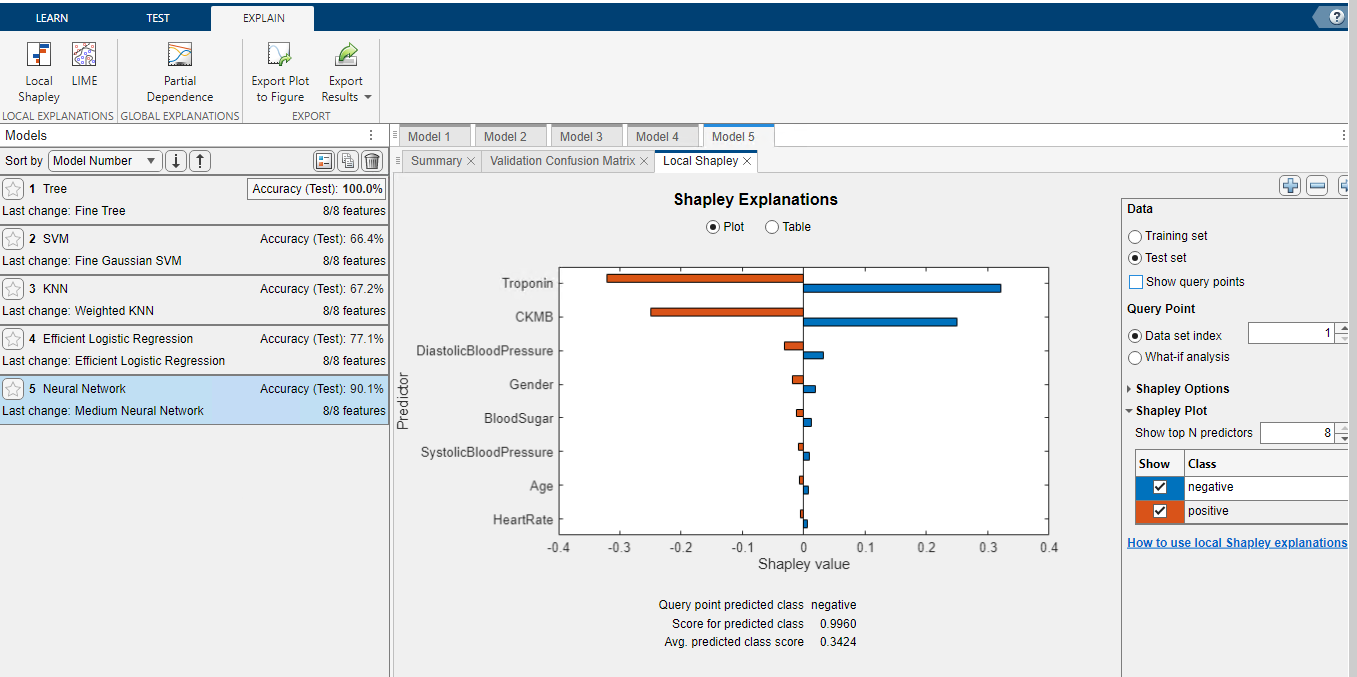
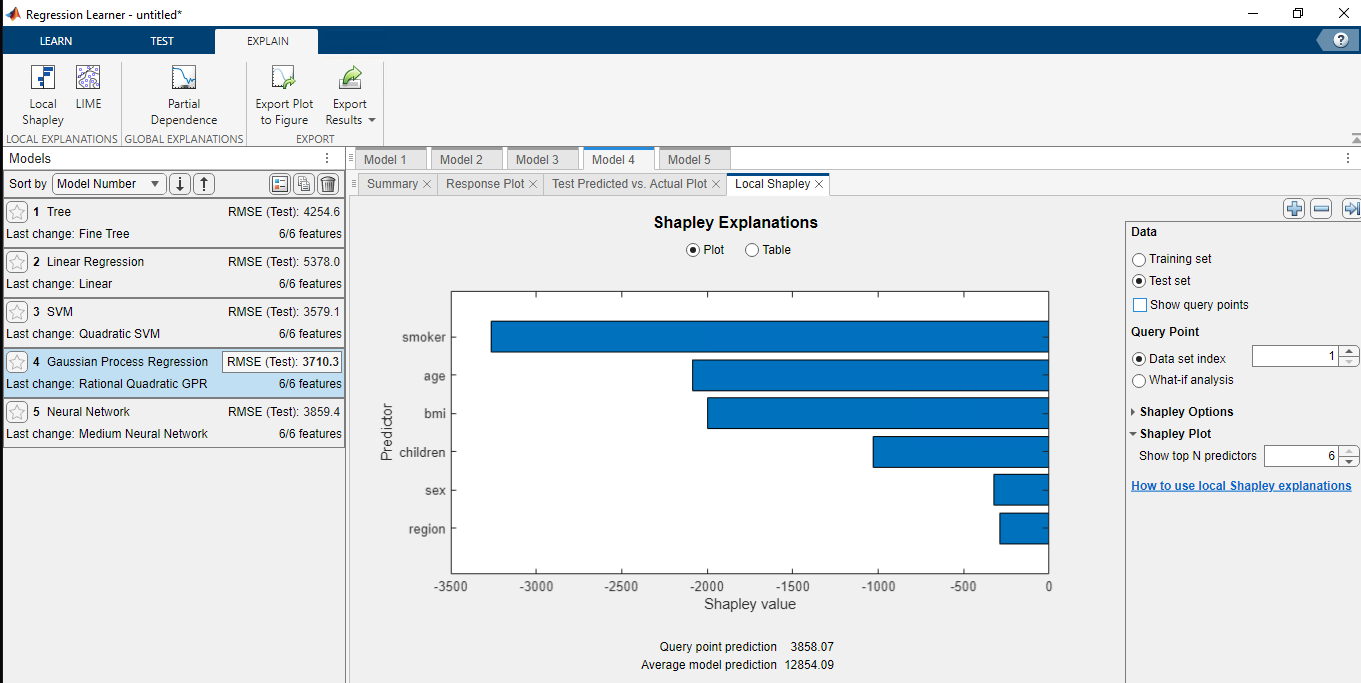
Przechodząc do zakładki EXPLAIN i wybierając Local Shapley możemy sprawdzić, które cechy miały największy wpływ na końcowy wynik.
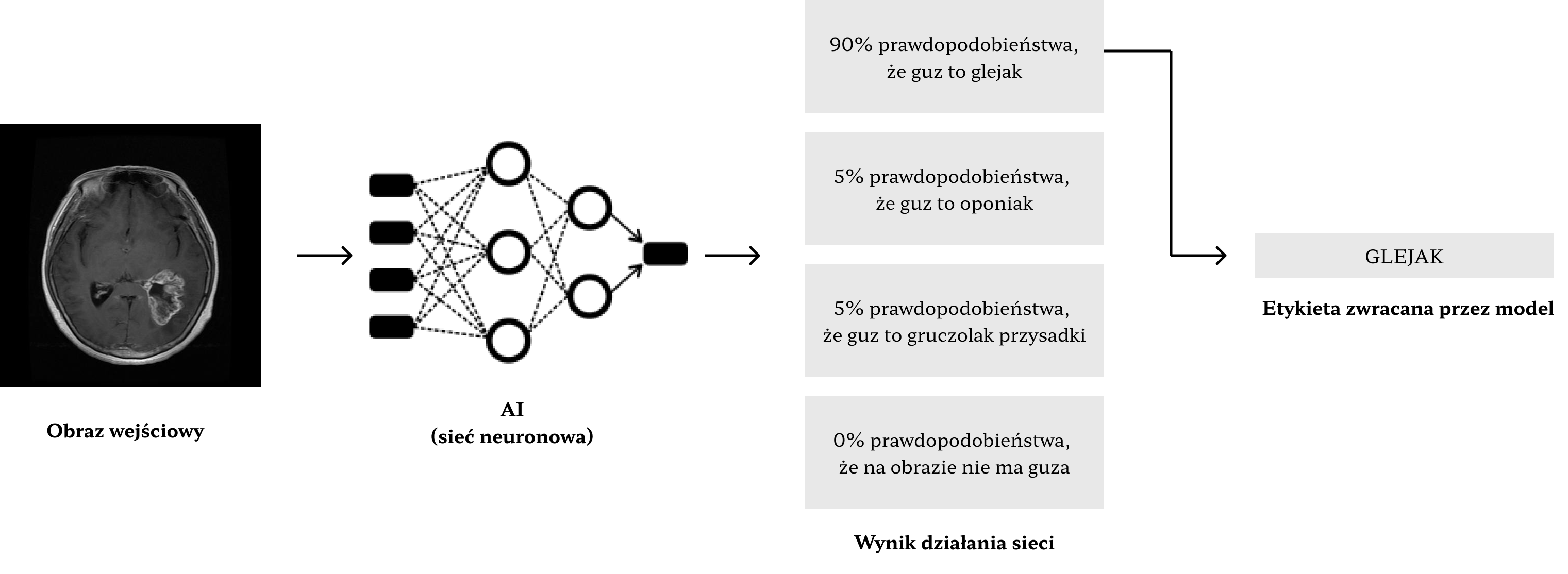
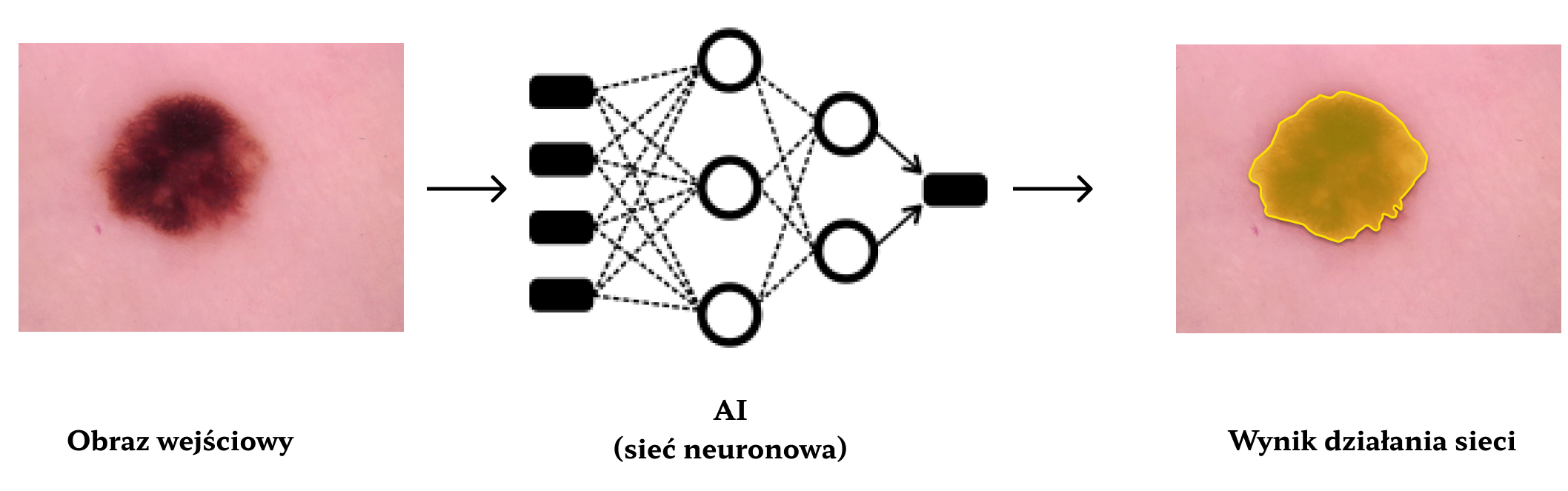
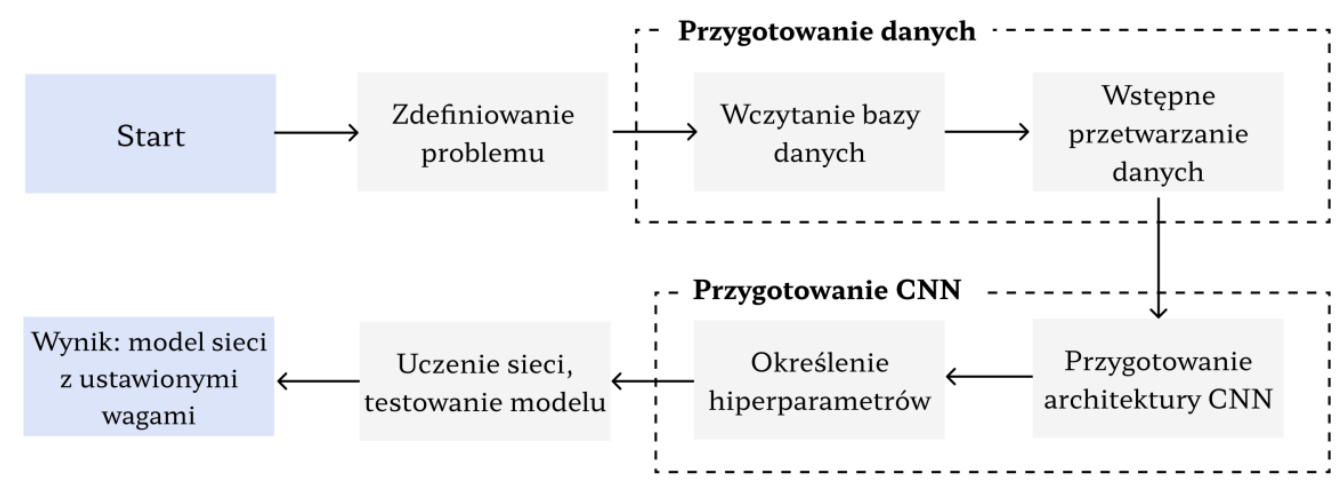
Prace nad uzyskaniem modelu głębokiego uczenia powinny rozpocząć się od precyzyjnego sformułowania problemu, który zespół chce rozwiązać. Od tego zależeć będzie budowa bazy danych i wybór architektury sieci.
1. Klasyfikacja: w oknie zaprezentowanym poniżej załaduj dane z folderu classification_data.
2. Segmentacja: analogicznie, załaduj dane z folderu segmentation_data.
Pomyślne zaimportowanie obrazów zostanie potwierdzone odpowiednim komunikatem.

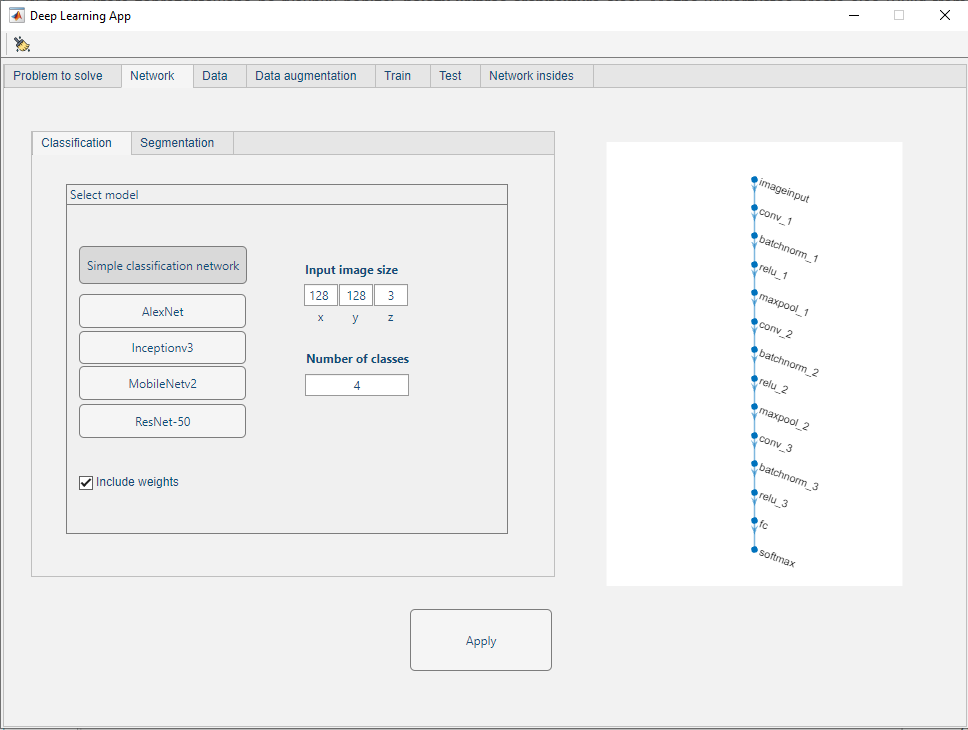
W oknie, które zaprezentowano na rysunku poniżej, należy wybrać architekturę sieci. W zależności od rozwiązywanego problemu należy wybrać odpowiednią zakładkę. Można wykorzystać prostą sieć (Simple classification/segmentation network) lub wykorzystać zaawansowane, ogólnodostępne architektury (AlexNet, Inceptionv3 itd.). Uproszczony schemat każdego z modeli jest wyświetlany z prawej strony okna (w przypadku dużych sieci schemat można przybliżać). Na tym etapie należy zadeklarować także wymiary obrazu wejściowego.
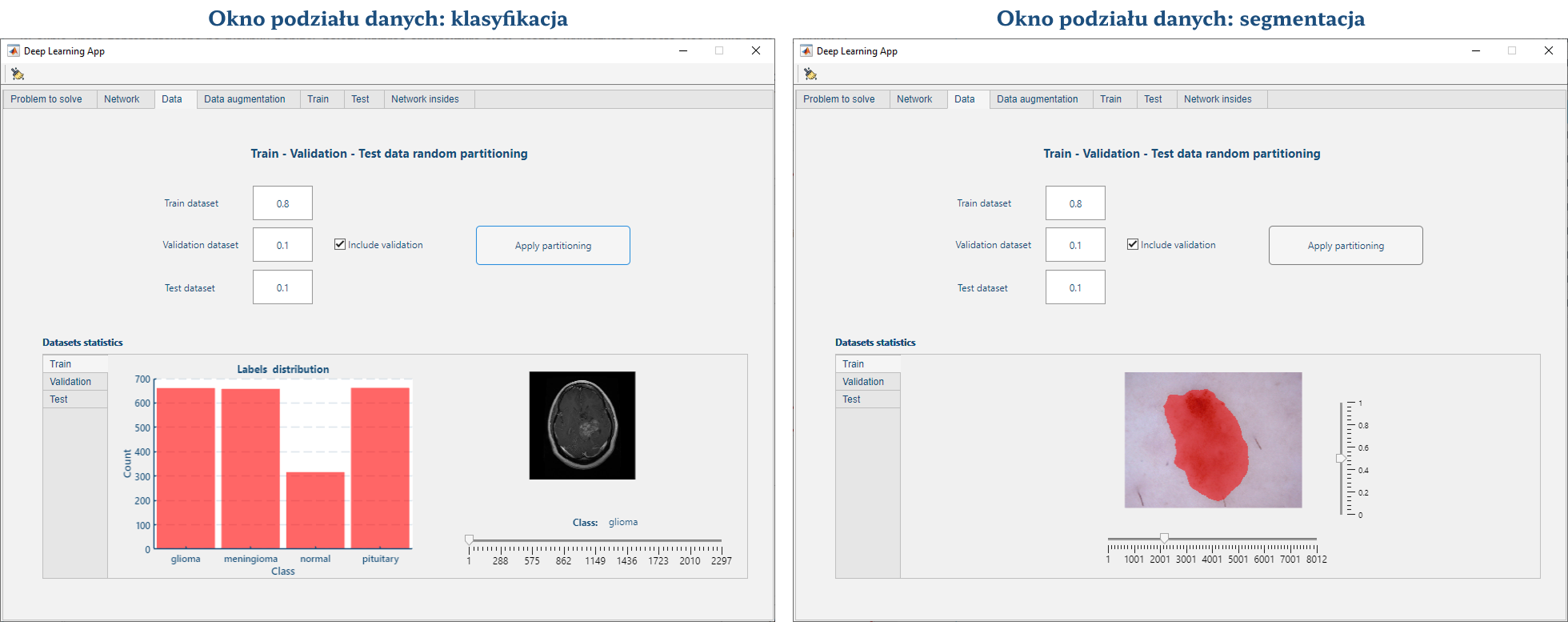
Ten panel pozwala dzielić bazę danych na podzbiory (ich części powinny sumować się do wartości 1):
- treningowy (największy, wykorzystywany do uczenia sieci),;
- walidacyjny (opcjonalny; wykorzystywany do walidacji sieci w trakcie uczenia);
- testowy (odseparowany; na tym zbiorze oceniane jest jak nauczona sieć radzi sobie na nie widzianych przez nią wcześniej danych).
Po zatwierdzeniu podziału za pomocą przycisku Apply, losowo pogrupowane dane można przejrzeć w panelu u dołu ekranu.
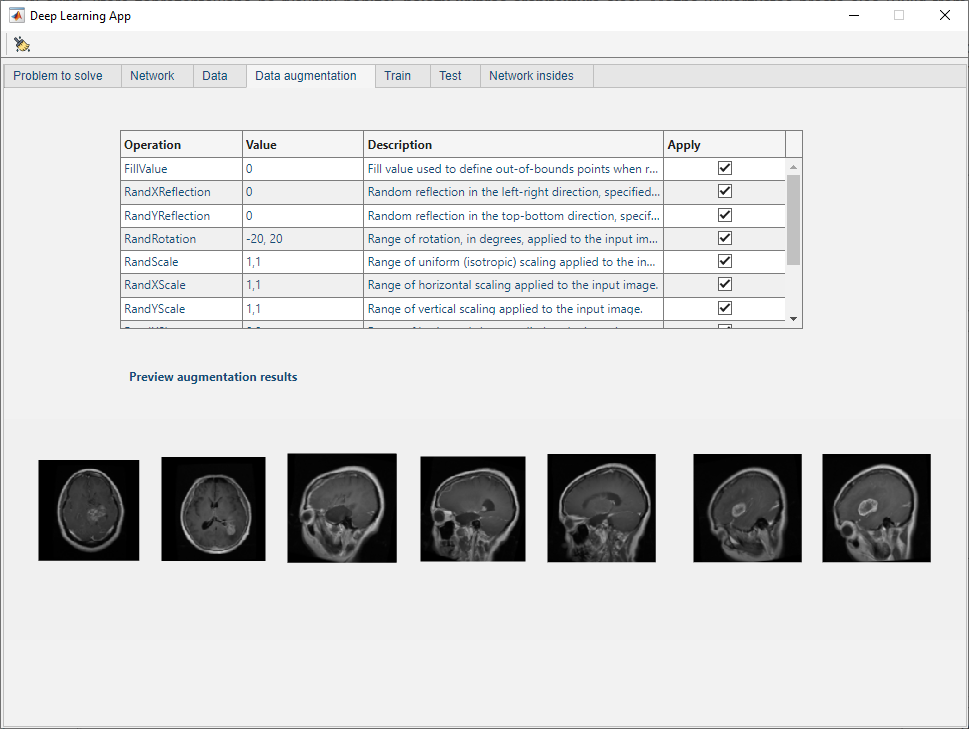
W panelu augmentacji danych zamieszczono tabelę, w której znajduje się lista operacji wykonywanych na obrazach w celu sztucznego poszerzenia zbioru danych. Kolumna dotyczącą wartości jest edytowalna (można zmieniać zakres danych). Kolumna Apply mówi o uwzględnieniu (kiedy opcja jest zaznaczona) lub braku uwzględnienia (kiedy pole wyboru jest odznaczone) danej operacji. Wynik augmentacji, która wykorzystuje aktualnie zaznaczone zmiany wyświetlana jest na dole okna.
Uczenie sieci należy rozpocząć od wyboru modelu (w zależności od problemu: classification_network lub segmentation_network). Następnie użytkownik powinien dobrać:
- optymalizator (ang. optimizer; w uproszczeniu: algorytm sterujący procesem uczenia),
- funkcję straty (ang. loss function; algorytm mierzy swoją dokładność za pomocą funkcji straty, tj. wartość, którą chcemy optymalizować),
- wybrane hiperparametry, m.in. liczbę epok (odnosi się do jednego całego przejścia danych treningowych przez algorytm) czy szybkość uczenia (ang. learning rate; określa jak bardzo należy zmienić model w odpowiedzi na szacowany błąd za każdym razem, gdy aktualizowane są wagi modelu).
Wybrane wartości zatwierdza się przyciskiem Train – rozpoczyna on również proces uczenia sieci (należy chwilę poczekać aż na wykresach z prawej strony okna zaczną pojawiać się wartości). W każdym momencie możliwe jest przerwanie uczenia i zapisanie sieci (Stop training).

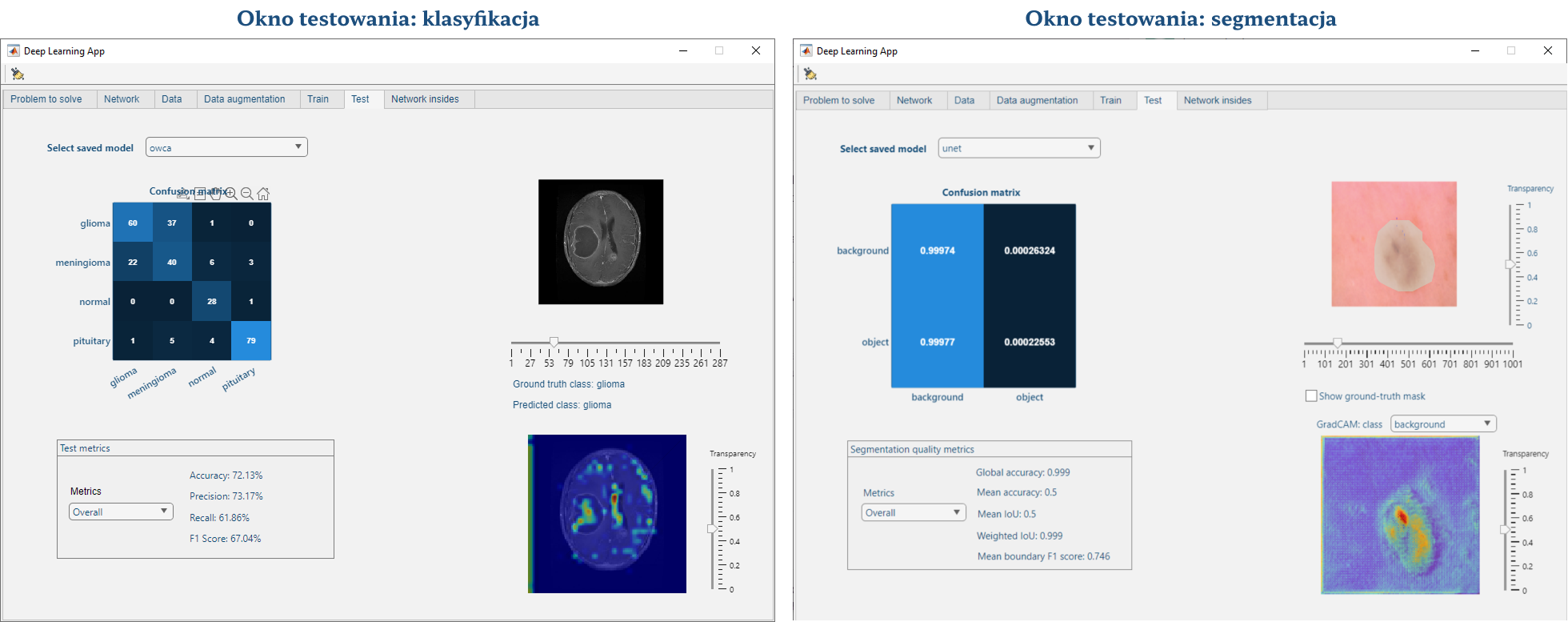
Panel testowania sieci pozwala na sprawdzenie dokładności działania nauczonego modelu na zbiorze testowym (czyli takim, którego sieć wcześniej “nie widziała”). Panel zawiera: macierz pomyłek (ang. confusion matrix; generalnie im wyższe wartości na przekątnej, tym lepsza skuteczność sieci), obiektywne metryki, podgląd danych testowych w prawej górnej części okna wraz z opisami eksperckimi (ang. ground truth class) oraz zwróconymi przez nauczoną sieć (ang. predicted class). Możliwe jest także wygenerowanie mapy GradCAM – wizualizację, które części obrazu miały największy wpływ na decyzję modelu (obszary żółte, pomarańczowe i czerwone wskazują na region większego zainteresowania sieci).
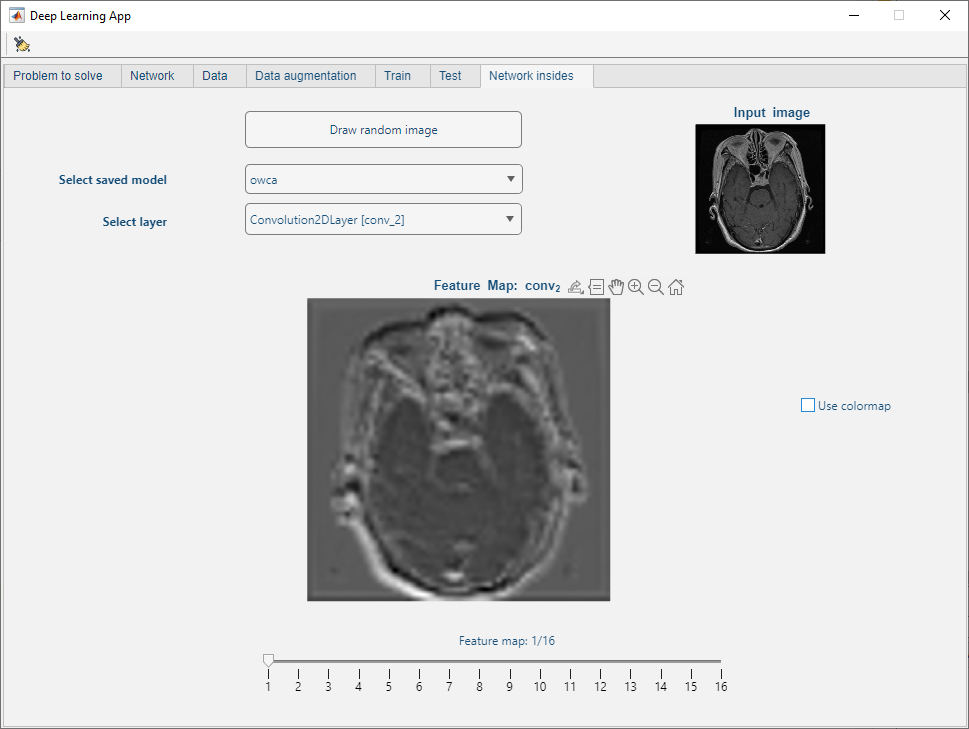
Ten panel pozwala na przyjrzenie się wynikom z poszczególnych warstw wybranej sieci. Warstwy te mają różne przeznaczenie i stoją z nimi różne operacje matematyczne na obrazach.